
While preparing for the SAS Business Analyst certification, Jiin and I were discussing a side project that we could complete during the winter break. We decided to build a movie recommendation engine for two reasons. First, neither of us had experience in this area, and second, this project would help strengthen our programming skills. We hope that this article inspires you to build your own recommendation engine or learn more about this topic!
Choosing a System
Generally, there are 3 types of recommendation systems: content-based, collaborative filtering, and a hybrid of the two. We decided to focus on collaborative filtering, both user-based and item-based.
The data include
- 100,000 ratings (1-5) from 943 users (who had rated at least 20 movies) on 1682 movies
- Simple demographic info for the users (age, gender, occupation, zip code)
- Genre information of movies
User-based Collaborative Filtering
The idea of the collaborative filtering algorithm is to recommend items based on similar past behaviors. In user-based collaborative filtering, the basic idea is that if user 1 likes movies A, B, C and user 2 likes movies B, C, D, then user 1 may like D and user 2 may like A. We built a recommendation engine that gives each user a tailored recommendation of movies based on what they watched previously and what they like.
The steps involved for creating a user-based collaborative filtering algorithm are:
1) Make a dictionary of users and all of the movies they rated
We first created a dictionary which contained all user IDs and the movies they have rated. We used the dictionary to efficiently search the movie items and rankings. For example, user 1 has rated movie Toy Story as 5 and GoldenEye as 3 then the dictionary would be like:
{‘1’: {‘Toy Story (1995)’ : 5, ‘GoldenEye (1995)’ : 3}}
2) Create a Euclidean Similarity function
After creating the dictionary, we created a function that calculates the Euclidean distance based on users’ ratings of each movie they watched. First, the function found the common movies between two users. Then, it got the lists of ratings from those two users. Using those lists, we calculated the euclidean distances, measuring the square root of the sum of squared differences between two ratings of the commonly ranked movies. Finally, the function normalized the euclidean distances, resulting in a range from 0 to 1.
3) Create a recommend function
Using the Euclidean similarity function, we created a function that recommends movies to the selected user. For example, let’s say that we want to recommend 10 movies to a user named Sunny. We evaluated the euclidean similarities of ratings between Sunny and other people. Based on the similarity score, we weighed more on the movies that Sunny didn’t watch and then recommended the ten most heavily weighed movies to Sunny.
4) Input the User ID and how many movies you want to recommend
Using the created recommendation function, we inputted the user ID, the number of movies we wanted to recommend, and the method we wanted to use to calculate similarities, in this case, euclidean similarity. This returns a list of movie IDs for the selected user.
5) Convert the movie ID to an actual movie title
The last step would be looping through the movie list to find the actual movie title based on recommended movie IDs. Figure 1 shows the ten recommendations for user ID 1.

Evaluation for User-based
To evaluate the user-based, collaborative filtering recommendation engine, we randomly removed 100 movies that user ID 1 watched. Figure 2 shows the 10 recommendation results from the dataset without 100 movies. Then, we compared the 10 recommendations with all the movies that user ID 1 watched. Of the 10 movies that our recommendation engine suggested, 7 appeared on the result, which makes the algorithm reliable!
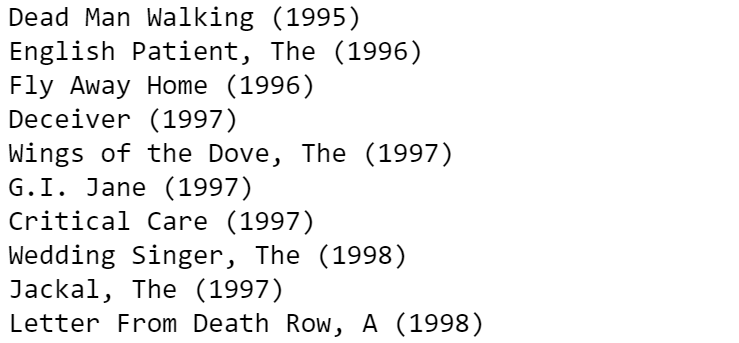
Item-based Collaborative Filtering
Instead of looking for users who have similar tastes in movies (user-based collaborative filtering), the item-based collaborative filtering algorithm finds movies that are similar to each other based on ratings that the user gave. Once we have a matrix of all movies and their ratings, we can recommend similar movies to any user. As an example, we will find five movies that are most similar to Snow White and the Seven Dwarfs.
The steps involved for creating an item-based collaborative filtering algorithm are:
1) Convert raw IDs into movie names and vice versa
Among the available datasets, we read in the u.item file. We then created a function that contains two dictionaries which store the movie names and their associated raw IDs as well as the raw IDs and their names.
2) Compute similarities between movies based on users’ ratings
We used the surprise package and tried various algorithms (e.g. KNNBasic, KNNWithMeans) and similarity measures (e.g. Pearson, cosine) to compute the similarities between movie ratings that all users rated. We then fed the matrix calculation into the K-Nearest Neighbor (KNN) baseline algorithm. We discovered that using KNN baseline and the shrunk Pearson correlation coefficient yielded the best result. The KNN baseline takes into account a baseline rating. The Pearson baseline calculates the similarities measures between all pairs of items using baselines for centering instead of means. The shrinkage parameter in Pearson helps to avoid overfitting when only few ratings are available.
3) Read the raw IDs <–> movie names mappings
4) Retrieve inner IDof Snow White and the Seven Dwarfs and inner IDs of the nearest neighbors of Snow White and the Seven Dwarfs
The algorithm will convert Snow White and the Seven Dwarfs’s raw ID to an inner ID that is associated in the model and return the kth nearest neighbors of that inner ID.
5) Convert inner IDs of the neighbors into movie names
The last step would be calling the function that created the 2 dictionaries (raw IDs <–> movie names) to find the actual movie title based on recommended kth nearest neighbors.
Evaluation for Item-based
To evaluate the Item-based Collaborative Filtering recommendation engine, we compared our results with Google’s search engine. For example, when we searched “Snow White and the Seven Dwarfs similar movies,” Google returned with “Cinderella,” “Sleeping Beauty,” “Snow White,” and “Pinnochio,” etc.
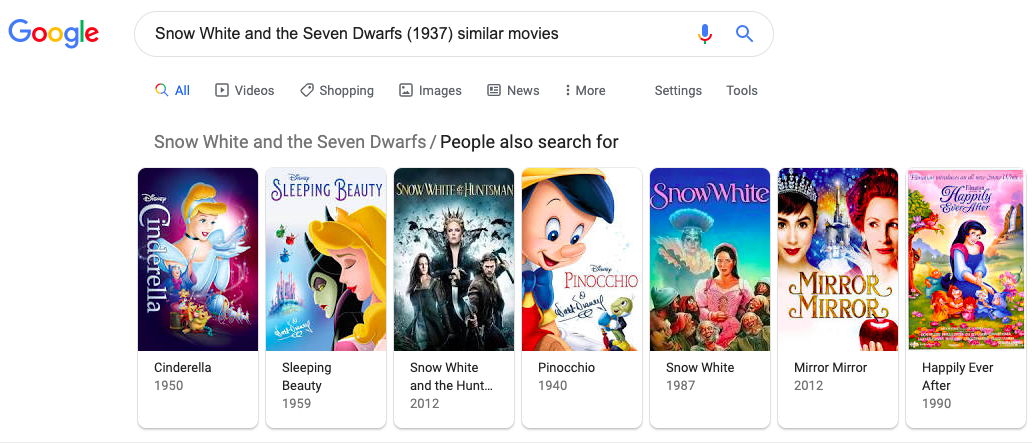
Out of the 5 movies that our recommendation engine suggested, 4 of those appear on Google’s search result. To us, this was a good start!

Further Consideration
The collaborative filtering algorithm is generally based on past behaviors, not on the context. Additionally, the user-based collaborative filtering is computationally expensive because the algorithm has to compare all the pairwise of users’ behavior. With the item-based collaborative filtering, the algorithm weighs more on popular movies. In other words, the system rarely recommends new movies.
One of the ways to improve these issues is the content-based algorithm. The algorithm recommends movies based on movies’ features. This would improve the cold-start problem of item-based collaborative filtering. However, it is not as personalized as the collaborative filtering algorithm.
Considering the pros and cons of the collaborative filtering algorithm, our recommendation engine could be improved to achieve better results. After reading this article, we hope you have some interest in recommendation engines.
Resources:
The Surprise Package used in Item-based Algorithm https://surprise.readthedocs.io/en/stable/
Distance Metrics in Machine Learning Modeling https://towardsdatascience.com/importance-of-distance-metrics-in-machine-learning-modelling-e51395ffe60d
Columnists: Cathy Tran and Jiin Son